This post builds on the new approach to transforming Twitter datasets generated by the TCAT tracking tool for analysis in Tableau which I’ve introduced in my recent posts. Often, we will be interested in exploring the structure of Twitter communities as they form around given hashtags or keywords – for instance to examine whether they really act as communities in a narrow sense, or are rather merely groups or publics who are in some way connected to the hashtag, but barely aware of each other’s presence.
In the past, we’ve used one of our Gawk scripts, metrify.awk, to generate a range of metrics which provided detailed information on the dynamics of a dataset over time, across individual users, and across different groups of accounts as defined by their level of activity; I explained that process in a multi-part post in 2012 (1, 2, 3, 4, and follow-up). With the move from yourTwapperkeeper and Excel to TCAT and Tableau, most of this analysis can now be done directly within Tableau itself, directly from the source TCAT dataset and the additional helper datasets which our TCAT-Process scripts generate. What’s still missing from the mix is a method for exploring the contribution of the different groups of accounts, though – this post outlines the steps for generating these metrics from within Tableau itself.
Introducing Percentile Groups
It’s well established that the distribution of activity levels across a given group of social media accounts will often follow a ‘long tail’ distribution: a very small number of accounts are very heavy contributors to a hashtag or a discussion, while a large number of others are contributing only very occasionally. The exact balance between these groups, and the exact nature of their respective contributions, can tell us a great deal about the dynamics of the overall Twitter public gathered around the shared hashtag or theme – the lead users may contribute in different ways from the least active users, for example by including more URLs in their tweets, or by taking a more discursive approach that features more @replies than retweets. We’ve used such observations very effectively in the past to distinguish between different types of hashtag events, and to pinpoint useful areas for further close reading of tweets.
What’s often used in this context is a 1/9/90 division between participants: ordered by their number of contributions to the conversation, the top 1% of accounts are identified as lead users; the next 9% as highly active users; and the remaining 90% as least active users. Other divisions are also possible, of course; what is most appropriate will depend on the specific dataset at hand, and on the research questions asked of it. For the purposes of this post, we’ll continue with the 1/9/90 division of accounts into three percentile groups.
Happily, it is fairly straightforward to create these percentile groups in Tableau. In the following discussion, I’m building on the processes outlined in my previous posts: so, we’ve already downloaded a full dataset export from TCAT (in my example, tweets about the attempted party leadership challenge to Australian Prime Minister Tony Abbott, using the #libspill hashtag and a number of related hashtags and keywords), and we’ve processed this dataset using the TCAT-Process scripts package I’ve made available here. We’ve also loaded and combined the resulting datasets in Tableau.
Now, the first new step is to create a new calculated field called ‘Percentile Ranking’ in Tableau, using the following formula:
RANK_PERCENTILE(COUNTD([Id]))
As usual, we are using COUNTD(Id) as the most reliable count of unique tweets; in a given list of items in Tableau, the RANK_PERCENTILE() formula then uses this count of tweets to calculate which percentile in the list a specific item occupies. The result will be a value between 0 (lowest percentile, 0%) and 1 (highest percentile, 100%).
In Tableau, we can now graph CNTD(Id) against From User Name, order the list by CNTD(Id), and add Percentile Ranking as a label; this generates an ordered list of participant accounts and shows their percentile ranking:

By this ranking, accounts with a Percentile Ranking greater than 0.99 are in the top 1% of lead users; accounts with a ranking between 0.9 and 0.99 are in the next 9% of highly active users; and the remainder of accounts with a ranking below 0.9 are in the bottom 90% of least active users.
However, in our further analysis we cannot use the Percentile Ranking field directly, as it is always freshly calculated depending on what fields are graphed against each other; we therefore have to persistently allocate accounts to the three groups we’ve defined. This is where Tableau gets uncharacteristically cumbersome for a moment:
- First, add Percentile Ranking to Filters, and filter for accounts with a ranking of at least 0.99:

- Next, click anywhere into the white space in the graph, and press CTRL-A to select all visible rows. Mouse over one of the rows, and click the paperclip icon to create a group:

- The new group will appear in the Dimensions sidebar, as “From User Name (group)” – rename it to something more meaningful, such as “LU” (for Lead Users).
- Remove LU from the Color field, where Tableau has placed it automatically.
- Change the Percentile Ranking filter to a range of values between 0.9 and 0.99, and repeat the previous steps – call this new group “HA” (for Highly Active).
- We now have two separate groups of accounts – LU and HA – and at least implicitly also a third group of accounts who belong to neither LU nor HA: these are our 90% of least active users. The final step is to combine these individual groups into one unified categorisation scheme which we can use in our further analysis: in the Dimensions sidebar, shift-click on the two groups to select them, right-click on one of them, and select Combine Fields – this finally creates a new combined field that permanently assigns each user to one of the three groups:

- Finally, let’s rename the new combined field “LU & HA” to “Sender Groups”.



(The overall process will remain the same for different percentile cutoffs, of course, and is even easier if you make only a simple distinction between a lead user group and the remainder of the userbase – for a 20/80 split, for example, simply create one group for accounts ranked above .8. However, finer gradations between multiple subgroups usually generate more useful analysis.)
Analysing the Groups’ Contributions
Having created these groupings, we can now begin to use them in our analysis. First, we should determine how many accounts there are in each of our groups, by showing the count of unique user names – i.e. CNTD(From User Name) – for each of the groups (note that I have also added a Grant Total row by selecting Analysis > Totals > Show Column Grand Totals):

By default, Tableau names the groups after the combination of selection criteria that the combined Sender Groups field was constructed from – but from the membership size of the groups listed above we know that the smallest group (the first row in the image above) must be the 1% of lead users, the second the 9% of highly active users, and the third the remainder of the 90% least active users. Right-clicking on each field and selecting “Edit Alias…” allows us to rename these fields to something more user-friendly.
It is also notable that while my dataset contains a total of 134,518 unique user names, the lead user group is made up of 1,347 accounts, and the two top groups together number 14,396 accounts in total – more than the 1% or (combined) 10% of 134,518 that they should contain. This is not an error, but simply a sign that Tableau does not play favourites: if there are multiple accounts at the boundary between two groups which equally fulfil the requirements for belonging to the higher-ranked group, Tableau will include them all, rather than arbitrarily sending some of them to the lower group in order not to expand the higher percentile group beyond the top 1% or 10%. In my sample dataset, for example, the cutoff for belonging to the lead user group was a total of 43 tweets sent, and multiple accounts had reached exactly that number.
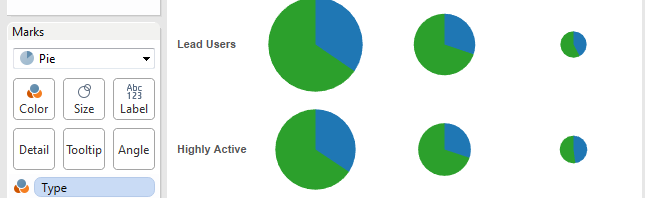
Next, we might want to explore the number and types of tweets sent by each group – so here, I’ve graphed Sender Groups against CNTD(Id), and coloured by Type (again with an added Grand Total column). What becomes evident in my sample is that the 1,347 lead users contributed more tweets than each of the other two groups, and that they were especially active in sending @mentions and retweets:

Replacing Type with Hashtag as the field determining colour, we can also determine highly divergent hashtagging practices – the lead users almost always included a hashtag, while almost two thirds of the tweets posted by the least active users did not contain hashtags (note again that the tweet numbers are increased beyond the previous graph here, and the percentages add up to more than 100%, because tweets can contain two or more hashtags). Incidentally, I’ve displayed the percentages by adding CNTD(Id) to Label and calculating its value as a percentage of total, using Table (Down) as the calculating method:

Many further permutations of these analyses are also possible, of course – we might explore, for example, whether there are differences in the URLs each group are sharing (are they using distinctly different domains as their sources of information?), or whether they are tweeting from notably different devices (as indicated by the Source field).
Further, we can also examine the contributions by these groups over time:

In my example, this shows that the lead users are responsible for a volume of tweets that usually closely matches that contributed by the (much larger) group of highly active users, while the least active users are less engaged during peak times, but make up for this by maintaining greater levels of activity outside of peak periods. This could also indicate that the least active group contains a range of users whose tweets showing up in our dataset as false positives (e.g. because they use the term ‘spill’ in non-#libspill-related contexts), which could be a good argument for excluding this group from the analysis altogether.
Using Percentile Groups Elsewhere
While this post has focussed on defining groups of accounts based on their active contributions to a dataset (i.e. the number of tweets they posted), the same approach can also be used for other distributions where grouping may be useful. For example, we might instead list the accounts being @mentioned (based on the To User field which the TCAT-Process scripts generate – not the unreliable To User Name field which the Twitter API itself provides) against the number of tweets mentioning them (via CNTD(Id)), and again calculate their percentile ranking. In fact, we can use the Percentile Ranking field we defined at the start of this post – it performs a new calculation for any list of items it is being applied to:

We should exclude “Null” from this list (which collects all the tweets which did not @mention or retweet another user), and can then again define a number of percentile groups following the process outlined above. For my sample dataset, this results in a group of 454 “Most Visible” accounts (the 1% of accounts who received the most @mentions and retweets), 4,596 “Highly Visible” accounts (the next 9%), and 40,272 “Least Visible” accounts (the remaining 90%). Note here, though, that by default Least Visible will contain the “Null” recipient (as Least Visible is simply a collection of all recipients that are not included in the other two groups), so we will need to manually filter out this recipient from all further analysis.
I’ve combined these groups into a Receiver Groups field, which we can now also use for some interesting analysis. First, for example, as expected the most visible accounts command the majority of @mentions and retweets:

Second, they are also especially popular with the most active participants in the discussion. Note especially how the least visible accounts are mainly mentioned by the least active participants – it seems that there are several separate discussion circles here:

And finally, turning the interactions between the various sender and receiver groups into a matrix and adding some further Tableau functionality into the mix, here’s a nice graph to end on. This shows the volume of activity from each sender to each receiver group, and breaks it down into @mentions and retweets:

Again, similar rankings can of course also be created for many of the other fields in our dataset – for example for the most frequently shared URLs (at the domain level, or for each fully qualified URL), the most prominent hashtags, even the most widely used tweeting platforms. Given the approaches I’ve outlined here, I hope these will be relatively easy to calculate now.