In my previous post, I introduced a new set of Gawk scripts to extract a range of additional information from standard TCAT datafiles, in order to enable their use for data exploration, analysis, and visualisation in Tableau. After running the TCAT-Process scripts, we now have the following datafiles:
- datafile.csv – the original TCAT dataset (a full export of all tweets and metadata)
- datafile-tweettypes.tab – a helper table which for each tweet lists the users mentioned, and the type of mention (‘@mention’ or ‘retweet’) made for each user; for tweets not containing any mentions of other users, the type is set to ‘original’.
- datafile-hashtags.tab – a helper table which for each tweet lists the hashtags it contains.
- datafile-urlpaths.tab – a helper table which for each tweet lists the short URLs and resolved destination URLs it contains, as well as the domain and domain and first path component of the resolved URL.
In combination, these datafiles enable a very wide variety of Twitter analytics in Tableau – replacing many of the processing steps that previously required a number of additional Gawk scripts, in fact.
In this post, I’m using a TCAT dataset on the recent attempted leadership spill in the Australian federal Liberal Party to demonstrate how to use these datafiles for Twitter analysis.
Linking the TCAT-Process Outputs in Tableau
The first step in using these datafiles is to relate them to each other in Tableau. So, after opening Tableau, I’m first connecting to the original Tableau dataset. Second, I’m dragging the tweettypes.tab datafile which the TCAT-Process script has created next to my main dataset. By clicking on the circles between them, I can now choose a Left Join, and Tableau already correctly suggests joining them on the ID field:

This means that for every tweet ID listed in the main TCAT dataset, Tableau now also reads in the datapoints from the tweettypes.tab datafile that relate to the same tweet ID. Note that – because tweets can mention multiple other users at the same time, and can thus be both @mentions and retweets at the same time – this means that the same tweet in the main dataset can now have multiple corresponding datapoints from the tweettypes.tab file.
We’re repeating the same process with the hashtags.tab and urlpaths.tab datafiles. Again, we’re using a Left Join, and again this means that multiple datapoints from these datasets may relate to the same tweet (if it contains multiple hashtags or URLs). By clicking on the gears icon that appears when mousing over the datafile names, a number of other useful parameters can also be set:

Most importantly, the character set should be set to UTF-8, and (to be on the safe side) the text qualifier should be set to None – but make sure it remains set to double quotes (“) for the main TCAT dataset.
Once all of these parameters are set, we can select the Connection method (make sure you use Extract for larger datasets), and click on Go to Worksheet.
Working with TCAT Data in Tableau
Before we begin the analysis, some housekeeping and setup will be useful. Tableau tends to place the tweet ID fields in its list of Dimensions, but we’ll be wanting to use a count of unique IDs in many of our analyses, so drag the ID field from each of the four data tables into the Measures list, and select Count (Distinct) as the default aggregation:

Further, for some datasets there may also be a need to adjust the timestamp of tweets in order to account for different timezones. To do so, right-click on the Created At field, create a calculated field, and use Tableau’s DATEADD function to adjust the time. My #libspill data is using AEST, for example, but as Canberra (where most of the spill action took place) is on daylight savings time and thus one hour ahead of AEST, I’m creating a new AEDT time field which adds one hour to AEST:

By dragging AEDT into Columns, and ID into Rows (where it will automatically become a count of unique IDs – CNTD(ID)) we can now chart the overall volume of tweets. Note that we’re using CNTD(ID) rather than the non-unique CNT(ID) or simply Number of Records because by joining our helper tables with the main dataset we now have more individual records than unique tweet IDs: each second or third user mention, URL, or hashtag in a tweet adds to the total count of records, so that – in my example – the 435,000 unique tweets contained in the #libspill datasets have become almost 980,000 records in the dataset.

Such basic volumetrics were already possible by using only the original TCAT dataset, but what comes next is possible only because of our data preprocessing using the TCAT-Process scripts. By dragging Type or Hashtag onto the colour, for example, we’re able to see what types of tweets or which hashtags were prominent at any one point (click to enlarge):


Similarly, the preprocessing has extracted data on the major recipients of @mentions, and the major sources of URLs being shared. Here we can use the To User and Domain fields for colour coding, and for greater clarity I’ve limited the graphs to the top 10 in each case, and filtered out any tweets which didn’t mention another user or shared a URL, respectively:


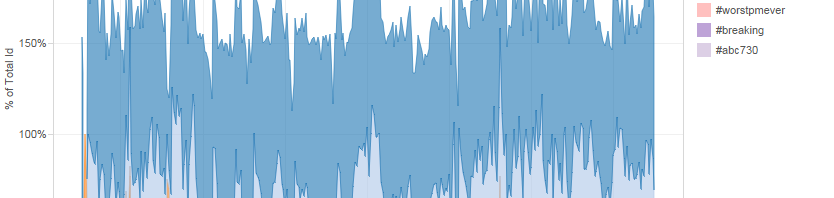
Such graphs can also be shown as a percentage of the total for each point in time. Note that in many cases the total will add up to more than 100%, as in my example below: my dataset was gathered largely based on the #libspill and #spill hashtags, but many of the tweets contained more than one hashtag.

Beyond Volumetrics
Many other combinations of datapoints are also possible – too many to step through here. However, some key analytical approaches beyond basic volumetrics are particularly obvious: for example, graphing From User Name or To User against CNTD(ID) and colouring by Type, we can see not only how many public tweets individual users sent or received, but also whether these were predominantly original tweets, @replies, or retweets, or a combination of them all – and by showing the two graphs alongside each other in a single Tableau dashboard, we can also create a useful comparative graph. Here, it’s important to use our new field To User, not TCAT’s and the Twitter API’s To User Name, which is only very rarely set to any actually useful value.

(Note that Tableau’s sort function seems to have some trouble sorting by CNTD(ID) – you may need to make some manual adjustments…)
It may also be useful to explore in which hashtag contexts specific users are @mentioned (for the purposes of illustration, here we’ve removed the generic #libspill, #spill, and #auspol hashtags, and included only the top 10 remaining hashtags):

Finally, there’s plenty we can do with the resolved URLs from the tweets, too. For example, here are the most widely shared domains (including the first component of the URL path, to gain a little more insight into what the content may be), and the types of tweets they’ve been shared in. One domain sticks out as being linked to only in original tweets – a clear indication of spam:

If we filter for retweets only, we can see which domains were the major information sources during the event. Beyond Twitter itself (which mainly shows up because of widely shared images in tweets), we see that the sites offering liveblogs on the day (Sydney Morning Herald, The Guardian, ABC News) are especially prominent:

And filtering the Domain field for links to Twitter content only, we can identify the most widely shared images (disseminated mostly through retweets, as we can see), as well as a set of what we might assume to be spam links (since Twitter itself flags them as potentially unsafe, and they were disseminated largely through hundreds of original tweets):

Of course as always it is then possible to drill down further into the data, and identify exactly which images and articles were most salient for participants in the Twitter discussion – in Tableau, that’s as easy as viewing the underlying data for any specific graph or datapoint.
So much for a quick overview of the potential analytical approaches which the TCAT –> Gawk –> Tableau process makes possible. Perhaps a future version of TCAT might even enable a direct export of the three additional helper tables our approach has created, without a need for the additional processing work in Gawk – but for the moment, the TCAT-Process scripts package should help to further enhance existing Twitter data analytics approaches, I hope.