About a month ago I introduced my new Gawk script metrify.awk, which generates a wide range of Twitter metrics for a given Twapperkeeper/yourTwapperkeeper hashtag or keyword archive. Even as I was writing those posts, though – and certainly while playing with the language metrics I discussed in my last post -, I started to find a few areas where metrify could provide even more information on the dataset. So, the time has come for a first service release which upgrades metrify.awk to add some more functionality (and fix a few inconsistencies along the way). This is a revision rather than a full rewrite of the script, so let’s call it metrify 1.2; it’s now available for download here, where it replaces the older version.
As before, the new version of metrify.awk is called as follows:
gawk -F , -f metrify.awk time=”[year|month|day|hour|minute]” [divisions=x,y,z,…] [skipusers=1] input.csv >metrics.csv
(divisions defaults to ‘90,99’ – i.e. a 90%/9%/1% split of the userbase – if it is not specified).
In this post, I won’t go from scratch through the entire range of metrics that metrify.awk generates; my original four-part post is still sufficient for that purpose. Rather, I’ll focus only on the major changes in this new revision, which relate mainly to part two of that series (and I’ve noted the updates in those posts as well, to avoid confusion): the metrics over time.
Changes to Metrics over Time
The first table generated by metrify shows the metrics over the chosen timeframe (e.g. day or hour), but it now contains a number of additional data points. The changes only concern the columns which contain metrics for the various user percentiles which are defined with the ‘divisions’ argument. Rather than providing information only on the number of users from each percentile which are actively participating during each timeframe (expressed as a percentage of the total number of currently active users), as metrify 1.0 did, revision 1.2 provides a number of further metrics:
- the number of users from each percentile which are currently active, and what percentage of the total currently active userbase that number represents;
- the number of tweets from users in each percentile which were made during the timeframe, and what percentage of the total current volume of tweets that number represents.
Here’s a comparison of the relevant output columns between versions 1.0 and 1.2:
| metrify.awk 1.0 | metrify.awk 1.2 |
| number of current users from least active x% (< u tweets) | |
| lowest x% users (<= u tweets) | % of current users from least active x% (< u tweets) |
| number of tweets from least active x% (< u tweets) | |
| % of tweets from least active x% (< u tweets) | |
| number of current users from > x% group (> u-1 tweets; a of n users) | |
| users > x% (> u tweets; a of n users) | % of current users from > x% group (> u-1 tweets; a of n users) |
| tweets from > x% group (> u-1 tweets; a of n users) | |
| % of tweets from > x% group (> u-1 tweets; a of n users) | |
| number of current users from > y% group (> v tweets; b of n users) | |
| users > y% (> v tweets; b of n users) | % of current users from > y% group (> v tweets; b of n users) |
| tweets from > y% group (> v tweets; b of n users) | |
| % of tweets from > y% group (> v tweets; b of n users) |
(with the default settings, x% would be 90% and y% would be 99%; a, b, u, v, and n would depend on the dataset).
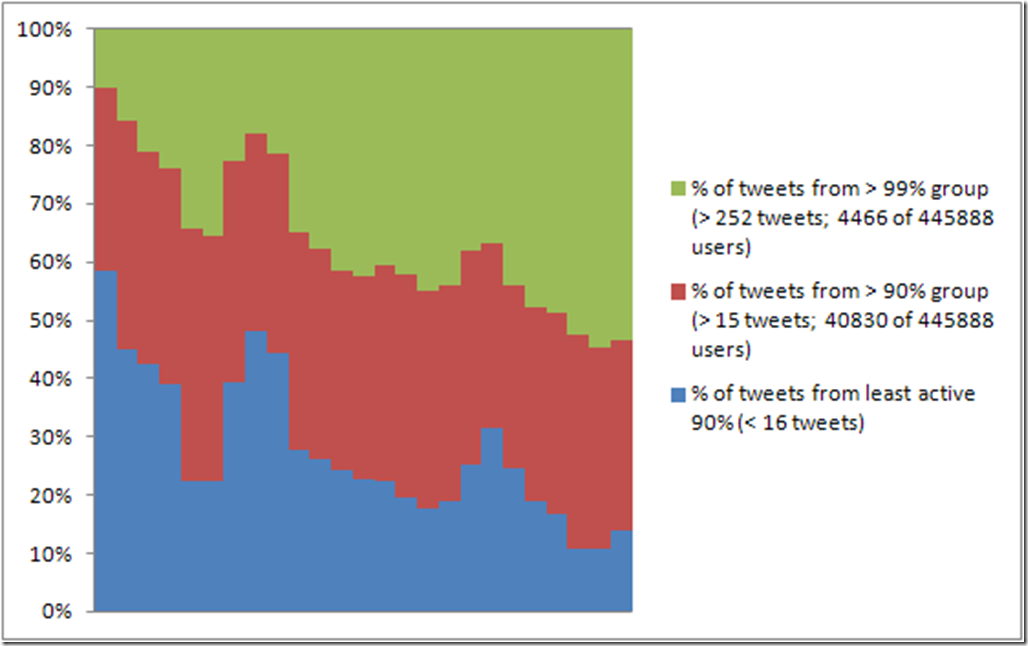
So, it now becomes possible not only to track what percentage of the total number of currently active users are from each of the percentiles we have defined, but also what percentage of the total volume of tweets during each period is contributed by each of the user percentiles. By way of example, here’s a comparison of those metrics for the #egypt dataset during February 2011:

Active users in the 90/9/1 user percentiles as percentage of total active userbase

Tweets by users in the 90/9/1 user percentiles as percentage of total current tweet volume
Unsurprisingly, the two charts move together – the greater the presence of a specific user group in the total active userbase, the greater their contribution to the current tweet volume – but only the second chart also tells the story of just how dominant the most active one per cent of users really is. Towards the end, they still only constitute slightly less than 20% of the total userbase participating during the final days of February – but more than half of all tweets posted at that time originate from them.
(At a later stage, I may also add functionality to track the use of different tweet types over time, by the different percentiles – but that’s a feature for metrify 1.5 or so.)
Other Changes
The only other notable change in this new revision is that the third of the tables generated by metrify.awk, which describes the participating users themselves, has gained a further column, ‘percentile’. This contains a simple descriptor of which of the various percentiles a user has been placed in, and thereby allows for an easier filtering of the list (using Excel’s data filter functions). For the standard 90/9/1 division of the userbase, fields in the column would contain one of the following four options for each user:
- > 99% – user belongs to the top 1% of most active users
- > 90% – user belongs to the top 10% of most active users, but is outside the top 1%
- > 0% – user belongs to the 90% of least active users
- none – user appears only in @reply or retweet mentions by others, but does not actively contribute to the hashtag
Additionally, and less obviously, I’ve also rewired how users are tracked through the dataset. In principle, this should be a very simple process: each user has both a unique numerical Twitter user ID, and a unique alphanumeric username. However, for some esoteric reason the user IDs returned by the Twitter search and streaming APIs, which Twapperkeeper uses to retrieve its datasets, do not always match, especially for older archives (or perhaps for older accounts?); the same user may have two completely different user IDs (thanks for John O’Brien for the details on this). This means that using the user IDs to track user activities in the dataset is unreliable. Usernames, however, may also be changed by the user at any point – @KRuddMP could become @KRuddPM when you least expect it. (Sorry, couldn’t resist!)
Still, as this doesn’t happen all too often, and given the unreliability of the numerical user IDs, metrify does use (lowercase) usernames as its internal tracking ID. The final output itself shows usernames in their properly capitalised form as we’ve first encountered it in tweets by the users themselves (they may also have chosen to change that capitalisation at a later date, though; we’re not checking for that), wherever possible; for users who are only mentioned, but don’t themselves tweet actively, we use the capitalisation which we first encounter.
Finally, one caveat remains: as before, metrify will take quite some time to process a large dataset, and is likely to run out of memory if it’s trying to generate full user metrics for such datasets. (There doesn’t seem to be any way to allocate more memory to Gawk – or to the shell it runs in -, so there’s little I can do to fix this.) Where full, detailed per-user metrics aren’t required, use the skipusers=1 command-line argument, and Gawk will only output the number of tweets contributed by each user, and the percentile they’ve been allocated to on that basis. And it will take a lot less time to do so.
So much, then, for this service update of metrify.awk. In a follow-up post in a few days, I’ll show how metrify metrics can also be imported into Gephi to turbo-charge our network visualisations of Twitter @reply and retweet networks…