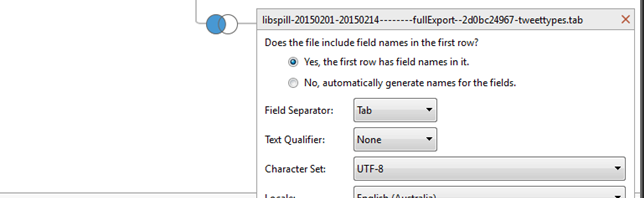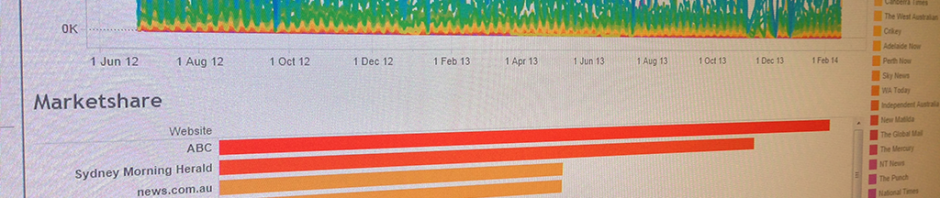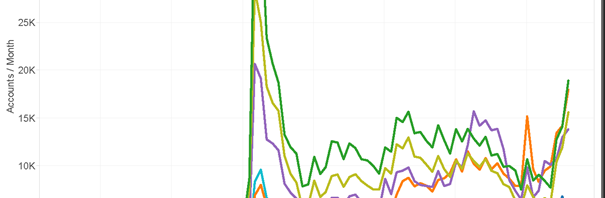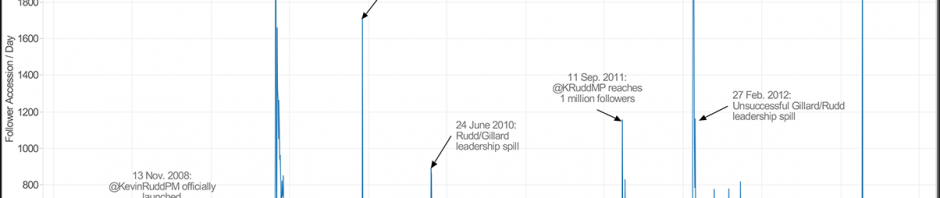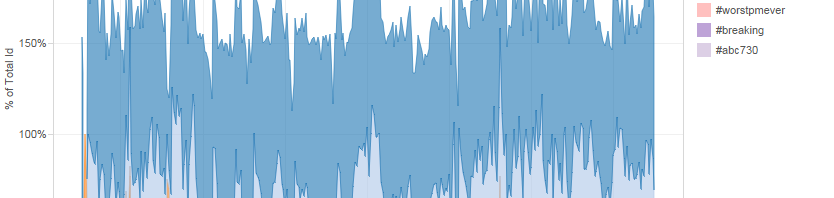
In my previous post, I introduced a new set of Gawk scripts to extract a range of additional information from standard TCAT datafiles, in order to enable their use for data exploration, analysis, and visualisation in Tableau. After running the TCAT-Process scripts, we now have the following datafiles: datafile.csv – the original TCAT dataset (a …
Continue reading “Using Gawk to Prepare TCAT Data for Tableau, Part 2”