Following on from my previous post about the methods we’re starting to use to make sense of the Australian blogosphere data we’re receiving from our colleagues at Sociomantic Labs, here’s a first look at what happens when we begin to visualise those data in the open source network visualisation software Gephi. Let me begin by making one thing very clear, though: this is based on as yet incomplete data, and should not be seen to say anything comprehensive about the shape of the Australian blogosphere. What we’re currently working with is:
- a highly incomplete list of Australian blogs that is biased towards those genres of blogging that we already know quite a bit about, and
- hyperlink data that hasn’t yet been cleaned up to contain only those links present in the blog posts themselves, rather than links elsewhere on the page.
So, as we’ve explained in our previous work, we can expect plenty of false positives (e.g. sites like WordPress.org which appear to be central to the blog network, but are so only because many blogs run on and link to WordPress – not because their posts actually talk about WordPress-related topics), and a network structure which overrepresents those sectors of the overall Australian blogosphere where we already know and track a majority of existing blogs (e.g. Australian politics, which we’ve studied in detail over the past few years).
With those caveats in mind, though, in this post I’ll work through the data as they are at the moment, largely to test our methods as we’ve established them and to see what insights can emerge from this process. I’m drawing here on a slice of hyperlink data from the nearly 8,300 blogs that we follow (also including a number of mainstream news sites which have RSS feeds – these will be sorted into a separate category at a later stage), collected between 17 July and 27 August 2010 – i.e. roughly coinciding with the Australian federal election campaign between 17 and 21 August. (Given this heightened activity, we should expect an overrepresentation of political blogs, therefore, even beyond the skew towards politics in our overall list of blogs.)
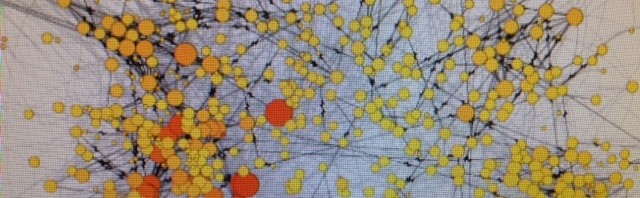
Working through the steps outlined in my previous post on processing the raw link data we receive from our fabulous research partners at Sociomantic Labs, I’ve extracted some 2.6 million individual hyperlinks during that timeframe, which I’ve imported into Gephi. To make a long story short, here’s the result:
In this visualisation of the network (full PDF here), I’ve excluded any sites which didn’t receive at least 3 inlinks during the time period. Other than that, the size of the nodes represents the number of incoming links they’ve received (their indegree), while the colour indicates their eigenvector centrality (which Gephi helpfully explains as “a measure of node importance in a network, based on the node’s connections” – in other words, not unlike Google’s PageRank it considers not just what incoming and outgoing links a node has, but also how well-connected those other nodes are). The links between the individual nodes in the network are coloured black for mutual links (where both sites link to one another) and grey for unidirectional links (where one site links to the other, but doesn’t receive a link back).
And here’s a version with the names of major sites made visible. Names of the minor nodes won’t be readable in the embedded version – but if you download the full PDF of the network you should be able to zoom in far enough to decipher them.
What begins to emerge from this version is a better sense of the clusters of heavily connected sites that exist in the data – as well as of the remaining limitations in data quality at this point. So, to begin with, WordPress.org and WordPress.com, as well as Feedburner.com, appear as prominent nodes here – but that’s not because they form part of any major conversations in the blogosphere, but simply because many blogs include purely instrumental links to these sites. In a later version of our work, we’ll exclude these sites, much as generic ‘kill words’ like ‘and’ and ‘or’ are excluded from automated textual analysis.
Also, we’re seeing a number of mainstream media sites appear in prominent positions – including, for example, Australian news sites like smh.com.au and news.com.au, as well as international sites like guardian.co.uk and news.bbc.co.uk. We’re tracking these sites ‘out of competition’, as it were, and will mark them as separate from the blogosphere proper at a later stage. These sites also tend to cluster together relatively closely because sites from the same stable (e.g. the suite of News Ltd. sites, from The Australian to the Courier-Mail)regularly link to one another in headers, footers, and sidebars. As we’re getting better at separating article content from ancillary material on a Web page, those links will gradually disappear from the network, and we would expect these sites to have relatively few outlinks, since the articles on most mainstream news sites tend to contain very few links.
But those limitations aside, what we’re already seeing in the network is a relatively large cluster of sites on the left of the graph, made up of sites (MSM as well as blogs) that deal predominantly with news and politics. In addition to domestic and international news sites, various Australian political blogs (such as Larvatus Prodeo, Club Troppo, John Quiggin, Peter Martin, Catallaxy Files, and the suite of Crikey blogs) appear as prominent nodes in the network (on both the indegree and eigenvector centrality counts). Many smaller – that is, less prominent – blogs cluster around them, but receive comparatively fewer inlinks. There’s even likely to be some further subdivision within this overall cluster, but I wouldn’t want to speculate too much on this point until we’ve had a chance to further clean our data.
At the same time, there clearly also appear to be a number of other clusters in the network, at some distance from this larger group of news and political sites (which might appear less prominent outside of election periods, incidentally – we’ll repeat this analysis again once political normalcy has fully resumed). Using Gephi’s modularity algorithm, then, here’s another version of the same graph, which assigns different colours to the various components of the network (full PDF here):
We see the main news and politics cluster depicted in a light green now (accounting for some 20% of all nodes in the visible network) – and Gephi seems to suggest that the nodes just above it are in fact separate enough to constitute a different cluster, in dark orange – these are sites like Ampersand Duck, Armagnac CD, and Cast Iron Balcony. Additionally, on the right of the graph there are three or four further substantial clusters, in red, yellow, green, and light blue. On closer inspection, their guiding themes emerge even just from the names of the blogs themselves:
- red: parenting – Mummy Time, My Three Ring Circus, Some Day We Will Sleep, Planning with Kids, Help Mum, Blog Chicks;
- yellow: food blogs – Not Quite Nigella, Here’s the Veg, Grab Your Fork, Nourish Me;
- green: arts and crafts – Hand Made Life, Craftapalooza, Lino Forest, Whip Up, Craft Blog, Six and a Half Stitches;
- light blue: design and style – The House That A-M Built, The Riley House Build, Space for Inspiration, Being Ruby, Bank on Good Style.
And we’re not done yet: at the top and bottom of the graph, there are a further few far-flung outliers that huddle closely together. Here, we find:
- at the very top: Global Trend Traders, Aussie Internet Marketing, 24/7 Wealth Creation;
- below and to the left: Life Coach Articles, Coach Snippets, Coach Resources;
- at the very bottom: Real Football, Down Under Football, The Football Tragic.
Some of these sites – and here I’m interested in the football ones in particular – may well be bridges into whole other sections of the Australian blogosphere that we’re simply not covering yet in our data gathering. I would not at all be surprised if the football blogs (and from the blog names, I’m assuming they mean FIFA-style football, not rugby or AFL) we have found are also part of a larger cluster of sports-related blogs in general, for example. On the other hand, without wishing to jump to any conclusions about the life coaching or wealth creation sites we’re seeing in the data, there’s also a chance that some of these sites are spam blogs (splogs), and that their distance from the mainstream blogosphere reflects that fact. For these outliers in particular, at any rate, it will be interesting to check what as yet unknown sites they link to, and whether those sites should be included in our overall list of Australian blogs.
So, as a first attempt at making sense of the blog network data we’ve gathered so far, I think this has been useful. As I’ve noted at the start, we’ll need to do plenty of further work in cleaning up the link data and expanding our list of known blogs, of course, but even this still somewhat messy dataset already shows that our overall approach is sound and that there are distinct populations of bloggers in the Australian blogosphere, who appear to cluster together mainly based on shared topical interests. But there’s also a good amount of interlinkage across clusters, it seems (both unidirectional, as the grey links in the graph indicate, and – less commonly, it appears – as a mutual connection between two sites). As we identify clusters in the network with greater accuracy, we’ll also be able to run textual analysis over the content of these blog clusters; beyond the blog titles themselves, this will give us a better impression of what these bloggers write about on a day-to-day basis.