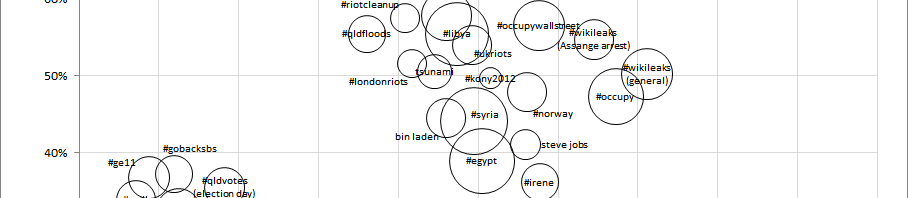
Taking a quick break from the AoIR 2015 liveblogging at snurb.info: today’s presentation by Fabio Giglietto, Luca Rossi and Jiyoung Kim got me thinking. They built on a paper by Stefan Stieglitz and me which compared some basic properties of a large number of hashtag datasets (and some keyword-based datasets, too), and used these to classify different hashtag uses (mainly distinguishing between crisis events and media audiencing).
Back then, we looked at the percentage of tweets containing URLs, and the percentage of tweets that were retweets, as well as the total number of tweets in each dataset:

From: Axel Bruns and Stefan Stieglitz. “Quantitative Approaches to Comparing Communication Patterns on Twitter.” In Klaus Bredl, Julia Hünniger, and Jakob Linaa Jensen, eds., Methods for Analyzing Social Media. 20-44.
I’m keen to update that study with new data from more recent hashtags, and we’ve already started to work through our own archived datasets to generate further metrics. But our datasets are limited to the research interests we’ve pursued over time, and to Australian and international topics.
So, I’m wondering whether we could build this up to a much larger collection by taking a collaborative, crowdsourced approach: if anyone else out there has Twitter datasets from the past few years, could you run a handful of quick analyses over your archives and share the results? What we’d need are:
- Hashtag(s) or keyword(s) used to capture the dataset
- Timeframe of capture (from/to date)
- Total number of tweets
- Total number of tweets containing URLs – using the regular expression /http/
- Total number of tweets containing retweets – using the regular expression /(\”@|RT @|MT @|via @)[A-Za-z0-9_]+/
You could leave those details in the comments attached to this post, or email them to me at a.bruns(at)qut.edu.au.
This is an experiment, in the spirit of AoIR collegiality. Would anyone be interested in sharing the metrics for their datasets? In return, I’d be very happy to include you as a contributing author in the paper we’ll eventually develop from this. Thanks in advance!
Great idea, here we go:
1) Hashtag #hhwahl (for regional election in Hamburg, Germany on 15th feb 2015)
2) Januar 19th to march 1st 2015 (6 weeks / 42 days)
3) Total number of tweets: 58.283
4) Total number of tweets containing URLs: 37.737
5) Total number of tweets containing retweets: 40.134
First response – thank you Jan ! Keep ’em coming !
I will soon provide the information about my dataset. In the meanwhile I’ve created a Google Form to simplify the data collection: http://goo.gl/forms/LR1nJmH39p
Brilliant, thanks Fabio !
It is an interesting idea. We collected Twitter data of 2014 Taiwan sunflower movement and 2014 Hong Kong umbrella movement. Each was collected by several keywords. I will provide the data to you later!
Fab – thanks, Yu-Chung !
Hi
Hashtag(s) or keyword(s) – #bigdata
Timeframe – Tue, 30 Jun 2015 12:39:44 to Sun Sep 27 2015 03:32:26
Total number of tweets -1040644
Total number of tweets containing URLs –
Total number of tweets containing retweets –
part of a set…
#analytics – 403748 Tue, 30 Jun 2015 13:17:30 to Sun Sep 27 2015 03:32:26
#iot 1051596 Tue, 30 Jun 2015 13:17:47 to Sun Sep 27 2015 03:32:26
#datascience 179621 Tue, 30 Jun 2015 13:18:14 to Sun Sep 27 2015 03:32:26
#deeplearning 113215 Tue, 30 Jun 2015 13:18:47 to Sun Sep 27 2015 03:32:26
#data 463725 Tue, 30 Jun 2015 13:19:06 to Sun Sep 27 2015 03:32:26
#machinelearning 139813 Tue, 30 Jun 2015 13:20:25 to Sun Sep 27 2015 03:32:26
#internetofthings 169557 Tue, 30 Jun 2015 17:57:39 to Sun Sep 27 2015 03:32:26
keen to get involved though with teaching commitments unable to spend enough time on this. Email at s.mcdermott@lcc.arts.ac.uk and I can forward you the url to access them directly.
Brilliant, thank you !
Is it mandatory to use the regular expressions? Due to the structured nature of the JSON-format one might simply count the occurrences of the respective field (or entities). My data is stored in a MongoDB, so it was more convenient to use it’s aggregation-functionality (thus, the data might not be comparable, but I will replicate that with the (imo more error-prone) regular expressions later on. Anyway, you`ll find my preliminary data in Fabio’s form.
Brilliant, thank you. Nothing’s mandatory – but I don’t think the JSON fields in the API payload from Twitter necessarily pick up on all instances of what we would classify as a retweet (i.e. RT, MT, HT, via, “@, etc.)…
I got a dataset of Fortune 1000 CEOs’ tweets in 2014, I’m not sure if it can be useful to you because it contains a variety of hashtags.
Hi Vincent,
thanks for this. That’s an interesting dataset, but you’re right, it’s probably beyond the scope of this exercise as we’re focussing on hashtags and keywords. We have a bunch of datasets focussing on tweets by and to populations of politicians, and those datasets are outside of the scope for this one, too…
Axel